La vie 3.0
Etre humain à l'ère de l'intelligence artificielle
- Par Max Tegmark,
- Traduit de l’anglais (États-Unis) Julien Bambaggi
Quai des Sciences
2018
448 pages
Citer cet ouvrage
- TEGMARK, Max,
- Traduit de l’anglais (États-Unis) BAMBAGGI, Julien,
- Tegmark, Max.,
- et al.
- Tegmark, M.,
- Traduit de l’anglais (États-Unis) Bambaggi, J.


Les trois étapes de la vie : évolutions biologique, culturelle et technologique. Life 1.0 n’est capable de refondre ni son hardware ni son software pendant la durée de sa vie. Les deux sont déterminés par son ADN et seule l’évolution, sur de nombreuses générations, peut y apporter des changements. En revanche, Life 2.0 peut modifier beaucoup de choses dans son software : les êtres humains peuvent acquérir des compétences complexes – langues, sports, métiers – et transformer radicalement leur façon de voir le monde et leurs objectifs. Life 3.0, qui n’existe pas encore sur Terre, peut revoir de fond en comble son software et son hardware sans avoir à attendre que l’évolution s’en charge au fil des générations.

La plupart des polémiques à propos de l’intelligence artificielle générale (qui peut atteindre celle des hommes sur des tâches cognitives) sont centrées sur deux questions : quand cela arrivera-t-il (si cela se produit un jour) et qu’est-ce que cela signifiera pour l’humanité ? Techno-sceptiques et utopistes numériques s’accordent sur le fait que nous ne devrions pas nous inquiéter, mais pour des raisons très différentes. Les premiers sont convaincus qu’une intelligence artificielle générale (AGI) de niveau humain ne verra pas le jour dans un avenir prévisible. Les seconds pensent que cela se produira mais qu’il s’agira certainement d’une bonne chose. Le mouvement pour une IA bénéfique pense que l’inquiétude est justifiée et utile parce que la recherche et les débats actuels sur la sécurité en IA augmentent les chances d’une issue profitable. Les Luddites* sont convaincus que l’issue serait une mauvaise chose et s’opposent à l’IA. Cette ligne est, en partie, inspirée par http://waitbutwhy.com/2015/01/artificial-intelligence-revolution-2.html.

La conférence de Porto Rico en janvier 2015 regroupa un panel remarquable de personnes occupées aux recherches en IA et sur des sujets voisins. Au dernier rang, de gauche à droite : Tom Mitchell, Seán Ó hÉigeartaigh, Huw Price, Shamil Chandaria, Jaan Tallinn, Stuart Russell, Bill Hibbard, Blaise Agüera y Arcas, Anders Sandberg, Daniel Dewey, Stuart Armstrong, Luke Muehlhauser, Tom Dietterich, Michael Osborne, James Manyika, Ajay Agrawal, Richard Mallah, Nancy Chang, Matthew Putman. Autres personnes debout, de gauche à droite : Marilyn Thompson, Rich Sutton, Alex Wissner-Gross, Sam Teller, Toby Ord, Joscha Bach, Katja Grace, Weller, Heather Roff-Perkins, Dileep George, Shane Legg, Demis Hassabis, Wendell Wallach, Charina Choi, Ilya Sutskever, Kent Walker, Cecilia Tilli, Bostrom, Erik Brynjolfsson, Steve Crossan, Mustafa Suleyman, Scott Phoenix, Neil Jacobstein, Murray Shanahan, Robin Hanson, Francesca Rossi, Nate Elon Musk, Andrew McAfee, Bart Selman, Michele Reilly, Aaron VanDevender, Max Tegmark, Margaret Boden, Joshua Greene, Paul Christiano, Eliezer Yudkowsky, David Parkes, Laurent Orseau, JB Straubel, James Moor, Legassick, Mason Hartman, Howie Lempel, David Vladeck, Jacob Steinhardt, Michael Vassar, Ryan Calo, Susan Young, Owain Evans, Riva-Melissa Tez, Krámar, Geoff Anders, Vernor Vinge, Anthony Aguirre. Assis : Sam Harris, Tomaso Poggio, Marin Soljačić, Viktoriya Krakovna, Meia Chita-Tegmark. Derrière l’appareil photo : Anthony Aguirre (photoshop réalisé par l’intelligence de niveau humain assise à côté de lui).

Bien que les médias aient souvent dépeint Elon Musk comme en désaccord avec la communauté de l’IA, il y a en réalité un large consensus sur le fait que la recherche sur la sécurité en IA est nécessaire. Ici, le 4 janvier 2015, Tom Ditterich, président de l’Association for the Advancement of Artificial Intelligence, l’association pour la promotion de l’intelligence artificielle, et Elon se félicitent : ce dernier s’est engagé, quelques instants auparavant, à financer un nouveau programme de recherche sur la sécurité en IA. On aperçoit derrière eux deux des membres fondateurs du FLI, Meia Chita-Tegmark et Viktoriya Krakovna.

De nombreux malentendus sur l’IA viennent de l’utilisation du même mot dans des sens différents. Je définis ici le sens que je leur donne dans ce livre. (Certaines de ces définitions seront abordées et expliquées plus précisément dans la suite de ce livre.)


L’intérêt de chacune des questions concernant l’IA dépend du niveau que cette dernière atteindra et de l’embranchement que suivra notre futur.


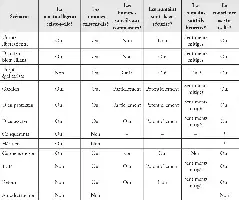
L’intelligence, définie comme étant la capacité à mener à bien des objectifs complexes, ne peut pas être mesurée à l’aide du seul QI mais uniquement sur sa capacité dans un éventail englobant toutes sortes d’objectifs. Chaque flèche indique le niveau d’aptitude actuel des meilleurs systèmes IA à atteindre divers objectifs, ce qui montre que l’intelligence artificielle actuelle est en général étroite, chaque système n’étant capable de réaliser que des objectifs très spécifiques. À l’inverse, le champ de l’intelligence humaine est extrêmement vaste : un enfant en bonne santé peut étudier et progresser dans pratiquement tous les domaines.

Illustration du « paysage des compétences humaines » de Hans Moravec. Ce qui est en altitude représente ce qui est difficile à réaliser pour des ordinateurs, le niveau de la mer indiquant ce qu’ils sont capables de faire.

Un objet peut servir de dispositif de mémoire commode s’il admet de nombreux états stables différents. À gauche, la balle peut coder quatre bits d’informations selon qu’elle se trouve dans l’un des 24 = 16 vallées. Ensemble, les quatre balles de droite peuvent aussi coder quatre bits d’information – un bit chacune.

Au cours des six dernières décennies, le prix de la mémoire des ordinateurs a été divisé par deux à peu près tous les deux ans, ce qui revient à les diviser par mille tous les vingt ans. Un octet vaut huit bits. Avec la permission de John McCallum, ces données sont tirées de http://www.jcmit.net/memoryprice.htm

Un calcul saisit une information et la transforme, mettant en œuvre ce que les mathématiciens appellent une fonction. La fonction f (à gauche) prend pour argument des bits représentant un nombre et calcule son carré. La fonction g (au milieu) prend les bits représentant une position de l’échiquier et calcule le meilleur mouvement pour les blancs. La fonction h (à droite) transforme les bits représentant une image pour calculer le texte d’une étiquette la représentant.

La fonction NON-ET prend pour arguments en entrée deux bits A et B et calcule en sortie un bit C d’après la règle suivante : C = 0 si A = B = 1 et C = 1 dans les autres cas. De nombreux systèmes physiques peuvent être utilisés en tant que fonction NON-ET. Dans l’exemple du milieu, les interrupteurs sont utilisés comme suit : 0 = « ouvert », 1 = « fermé ». Quand A et B sont tous les deux fermés, un électroaimant ouvre l’interrupteur C. Dans l’exemple de droite, ce sont des tensions qui traduisent les bits : 1 = « 5 volts » et 0 = « 0 volt » ; quand les éléments A et B sont placés tous deux sous une tension de 5 volts, les deux transistors laissent passer le courant et la tension de C tombe approximativement à 0 volt.

Tout calcul bien défini peut être réalisé par une combinaison judicieuse ne comprenant que des fonctions NON-ET. Par exemple, les modules d’addition et de multiplication ci-dessus prennent tous deux en entrée deux nombres binaires représentés par 4 bits et en ressortent un nombre binaire représenté respectivement par 5 et 8 bits. Les modules plus petits « NON », « ET » « XOR » (OU exclusif) et « + » (qui additionne trois bits séparés en un nombre binaire de 2 bits) sont un à un construits à partir de fonctions NON-ET. La compréhension de ce schéma est extrêmement difficile et pas du tout nécessaire pour le reste du livre. Je ne le fais figurer ici que pour illustrer l’idée d’universalité… et faire plaisir au geek qui est en moi !

Depuis 1900, le prix du calcul par une machine a été divisé par deux à peu près tous les deux ans. Les points montrent la puissance de calcul, mesurée en opérations à virgule flottante par seconde (FLOPS, pour FLoatting-point Operations Per Second) qu’on peut se procurer pour une somme d’environ 800 €. Le calcul qui définit une opération en virgule flottante représente environ 105 opérations logiques élémentaires telles que le changement de valeur d’un bit (bit-flip) ou les évaluations NON-ET.

Un réseau de neurones peut calculer des fonctions exactement comme un réseau de fonctions NON-ET peut le faire. Par exemple, on a appris à des réseaux de neurones à entrer les nombres correspondant à la luminosité de différentes images pixélisées et à en ressortir les probabilités que l’image représente certaines personnes. Ici, chaque neurone artificiel (cercle) calcule une somme pondérée des nombres récupérés en entrée (en haut) via les connexions (traits), met en œuvre une fonction simple et transmet le résultat (en bas), chaque couche qui suit ayant à calculer des caractéristiques de plus haut niveau. Les réseaux de reconnaissance faciale ordinaires contiennent des centaines de milliers de neurones. La figure n’en montre qu’un petit nombre pour des raisons de clarté.

Comment la matière peut effectuer une multiplication en utilisant des neurones et non les fonctions NON-ET de la figure 2.7. L’important n’est pas dans les détails, mais dans le fait que les neurones (artificiels ou biologiques) peuvent faire des maths et que la multiplication nécessite bien moins de neurones que de fonctions NON-ET. En option, quelques détails pour les matheux purs et durs. Les cercles effectuent des sommes, les carrés appliquent la fonction σ et les traits multiplient par la constante indiquée dessus. À gauche, les entrées sont des nombres réels, à droite des bits. La multiplication devient arbitrairement précise, à gauche quand a → 0, à droite quand c→ ∞. Le réseau de gauche est opérationnel pour n’importe quelle fonction σ présentant une courbure à l’origine (telle que la dérivée seconde σ″(0) ≠ 0), ce qui peut se prouver par un développement de Taylor de σ(x). Le réseau de droite réclame que la fonction σ se rapproche de 0 quand x devient de plus en plus petit, et de 1 quand x devient de plus en plus grand, ce qui se voit au fait que uvw = 1 seulement si u + v + w = 3. (Ces exemples sont tirés d’un article d’un de mes étudiants, Henri Lin : http://arxiv.org/abs/1608.08225.) En combinant de nombreuses additions et multiplications (comme ci-dessus), il est possible de calculer n’importe quelle fonction polynôme dont il est bien connu qu’elles peuvent approximer toute fonction suffisamment régulière.

« Groupe de jeunes jouant au frisbee » – ce sous-titre a été écrit par un ordinateur sans qu’il comprenne quoi que ce soit à ce que sont des jeunes, des jeux ou des frisbees.

Après avoir appris à jouer, à partir de rien, à Breakout d’Atari en utilisant l’apprentissage profond par renforcement pour optimiser ses scores, l’IA DeepMind a découvert la meilleure stratégie : percer un trou dans la partie la plus à gauche du mur de brique et laisser la balle rebondir tout autour permet d’accumuler des points très rapidement. J’ai dessiné des flèches pour montrer les trajectoires de la balle et la raquette.

L’IA AlphaGo de DeepMind a utilisé un mouvement extrêmement innovant sur la ligne 5, qui allait à l’encontre de millénaires d’expérience humaine, et qui s’est avéré décisif 50 coups plus tard pour battre le légendaire champion de go Lee Sedol.

Les robots industriels traditionnels sont chers et difficiles à programmer. Aussi la tendance va-t-elle vers des robots moins chers animés par une IA et à qui des ouvriers sans aucune compétence en programmation peuvent apprendre quoi faire.

Alors que les drones militaires actuels (ici l’US Air Force MQ-1 Predator) sont contrôlés à distance par des hommes, les futurs drones dirigés par IA pourront mettre les hommes sur la touche et utiliser un algorithme pour décider qui viser et tuer.

Croissance moyenne des revenus aux États-Unis au cours du siècle écoulé et répartition de ces revenus entre les différentes couches de la population. Avant les années 1970, la croissance est parallèle pour les riches et les pauvres ; après, l’essentiel de la croissance est allé aux 1 % disposant des revenus les plus élevés, tandis que les 90 % disposant des revenus les plus bas n’en ont pratiquement pas profité40. Les montants ont été corrigés de l’inflation et ramenés à leur valeur en dollars de 2017.

Le diagramme circulaire montre les postes de 149 millions d’Américains qui disposaient d’un emploi en 2015, avec les 535 catégories de l’US Bureau of Labor Statistics classées par popularité49. Tous les métiers qui emploient plus d’un million de personnes ont été étiquetés. On remarque qu’il n’y a aucun emploi d’un type nouveau avant la 21e place. Ce schéma est inspiré d’une analyse de Federico Pistono50.

Sunway TaihuLight, le superordinateur le plus rapide du monde en 2016, dont la puissance de calcul est sans doute plus grande que celle du cerveau humain.


Exemples de ce qui, d’après ce que nous connaissons, pourrait détruire la vie ou céduire irréversiblement son potentiel. Notre univers lui-même durera sans doute au moins 10 milliards d’années. Mais notre Soleil desséchera la Terre dans quelque chose comme un milliard d’années avant de l’engloutir, à moins que nous ne la déplacions à une distance de sécurité ; et notre galaxie entrera en collision avec sa voisine dans à peu près 3,5 milliards d’années. Bien avant – c’est presque une certitude, même si nous ne connaissons pas la date à laquelle cela se produira –, les astéroïdes vont marteler la Terre et de supervolcans provoqueront des hivers sans Soleil toute l’année. Nous pouvons faire appel à la technologie pour résoudre ces problèmes ou bien pour en créer de nouveaux – comme le réchauffement climatique, la guerre nucléaire, les pandémies provoquées ou en laissant les IA mal tourner.

Une unique bombe à hydrogène explosant à 400 km au-dessus de la Terre engendrerait une puissante impulsion électromagnétique pouvant mettre hors d’usage tous les appareils électriques sur une vaste zone. En déplaçant le point d’explosion vers le sud-ouest, la zone en forme de banane dépassant 37 500 volts par mètre pourrait recouvrir l’essentiel de la Côte Est des États-Unis. Tiré du rapport AD-A278230 (non classifié) de l’Armée US. Les couleurs ont été ajoutées.

Refroidissement moyen (en °C) pendant les deux premiers étés qui suivraient une guerre nucléaire totale entre les États-Unis et la Russie. Carte reproduite avec l’aimable autorisation d’Alan Robock11.

Une paire de cylindres d’O’Neill tournant en sens contraire peut fournir des habitats confortables, semblables à ceux des hommes sur Terre, s’ils sont en orbite autour du Soleil d’une façon telle qu’ils pointent en permanence droit sur lui. La force centrifuge issue de leur rotation fournit une gravité artificielle et trois miroirs escamotables peuvent transmettre à l’intérieur la lumière solaire et assurer un cycle jour-nuit de 24 heures. Les habitats plus petits disposés en anneau sont spécialisés dans l’agriculture. Avec l’aimable autorisation de Rick Guidice/NASA.

Vue intérieure de l’un des cylindres d’O’Neill de la figure précédente. Si son diamètre est de 6,4 km et qu’elle effectue une rotation toutes les deux minutes, la gravité apparente à sa surface sera la même que celle de la Terre. Le Soleil est situé derrière vous mais semble être au-dessus grâce à un miroir à l’extérieur du cylindre qui se replie pour la nuit. Des fenêtres étanches empêchent l’atmosphère de s’échapper du cylindre. Avec l’aimable autorisation de Rick Guidice/NASA.
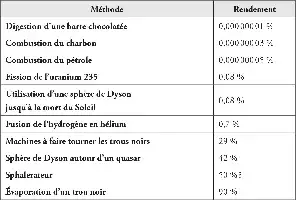
Rendement dans la conversion de la masse en énergie utile par rapport à la limite théorique E = mc2. Comme expliqué dans le texte, obtenir 90 % en nourrissant des trous noirs et en attendant leur évaporation est malheureusement trop lent pour être utile et accélérer le processus fait tomber considérablement le rendement.

Des technologies avancées peuvent extraire considérablement plus d’énergie de la matière que ce que nous obtenons en la digérant ou en la brûlant. La fusion nucléaire ellemême en récupère 140 fois moins que ce que permettent les lois de la physique. Des centrales énergétiques exploitant les sphalerons, les quasars ou l’évaporation des trous noirs feraient bien mieux.

Une partie de l’énergie cinétique de rotation d’un trou noir en rotation peut être extraite en envoyant une particule A près du trou noir, provoquant sa séparation en une partie C qui est absorbée et une partie B qui s’échappe avec davantage d’énergie que n’en avait A au départ.

Selon le modèle standard de la physique des particules, neuf quarks possédant la saveur et le spin appropriés peuvent se combiner pour donner trois leptons à travers un état intermédiaire appelé sphaleron. La masse totale des quarks (avec l’énergie des gluons qui les accompagnent) est beaucoup plus grande que celle des leptons. Le processus libère donc de l’énergie, comme indiqué par les flèches.
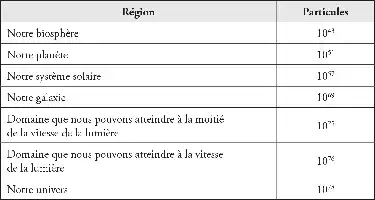
Nombre approximatif de particules de matières (protons et neutrons) dont la vie future peut espérer faire usage.

Notre univers – c’est-à-dire la région sphérique de l’espace à partir de laquelle la lumière a eu le temps de nous parvenir (nous sommes au centre) pendant les 13,8 milliards d’années depuis le Big Bang. Les motifs montrent les photos du bébé univers prises par le satellite Planck qui révèlent que, quand il n’avait que 400 000 ans, il consistait en un plasma presque aussi chaud que la surface du Soleil. L’espace se prolonge probablement en dehors de cette région et de la matière nouvelle apparaît à notre vue chaque année.

Dans un diagramme d’espace-temps, un événement est un point dont les positions horizontale et verticale codent respectivement le lieu et la date où il s’est produit. Si l’espace n’est pas en expansion (schéma de gauche), un cône délimite deux parties de l’espace en forme de « chapeau de clown » dont le seul point commun (le sommet) est notre position à nous sur Terre. Le « chapeau » du bas est la partie de l’espace qui peut nous affecter et celui du haut celle que nous pouvons affecter parce que rien ne peut se déplacer à une vitesse supérieure à celle de la lumière qui le fait à la vitesse d’une année-lumière par an. Les choses deviennent plus intéressantes avec un espace en expansion (schémas de droite). Selon le modèle standard de la cosmologie, nous ne pouvons voir et atteindre qu’une partie finie de l’espace-temps, même si l’espace est infini. Dans le schéma du milieu, qui rappelle une flûte de champagne, nous avons utilisé des coordonnées qui ne montrent pas l’expansion de l’espace : les mouvements des galaxies lointaines correspondent donc à des lignes verticales. De notre point de vue privilégié actuel, 13,8 milliards d’années après le Big Bang, les rayons lumineux ont eu le temps de nous atteindre uniquement depuis la base de la flûte de champagne et, même si nous voyagions à la vitesse de la lumière, nous ne pourrions jamais atteindre les zones à l’extérieur de la partie supérieure de la flûte, qui contient environ dix milliards de galaxies. Dans le schéma de droite, qui évoque une goutte d’eau sous une fleur, nous avons utilisé les coordonnées familières où l’on voit l’expansion de l’espace. Cela donne à la base de la flûte une forme de goutte parce que les zones sur les bords de ce que nous pouvons voir étaient, auparavant, très rapprochées.

Le design de Robert Forward pour une mission à voile à propulsion laser vers le système de l’étoile Alpha du Centaure situé à quatre années-lumière. Au départ, un puissant laser à l’intérieur de notre système solaire accélère le vaisseau spatial en appliquant un rayonnement de pression sur son aile photonique laser. Pour freiner avant d’atteindre la destination, la partie extérieure de la voile se détache et réfléchit le laser vers l’arrière sur le vaisseau.

Estimations du futur lointain. Toutes, à l’exception des 2e et 7e, ont été faites par Freeman Dyson. Il avait fait ces calculs avant la découverte de l’énergie sombre, ce qui peut entraîner plusieurs sortes de « cosmocalypses » dans 1010 à 1011 ans. Peut-être les protons sont-ils complètement stables. Si ce n’est pas le cas, les expériences suggèrent qu’il faudra 1034 ans pour que la moitié d’entre eux se désintègrent.

Nous savons que notre univers a débuté par un épisode chaud, le Big Bang, il y a environ 14 milliards d’années. Il a connu une phase d’expansion, de refroidissement et ses particules ont fusionné en atomes, étoiles et galaxies. Mais nous ne connaissons pas son destin final. Parmi les scénarios avancés, il y a le Big Chill, (le grand froid, une expansion éternelle), le Big Crunch (l’effondrement terminal), le Big Rip (la grande déchirure, une expansion à un rythme infini qui aboutit à tout mettre en pièces), le Big Snap (le grand clac, le tissu de l’espace révèle une nature granulaire mortelle quand il est trop étiré) et les Death Bubbles (les bulles de la mort, l’espace se « glace » en bulles mortelles dont l’expansion se fait à la vitesse de la lumière).

Si la vie évolue indépendamment en divers points de l’espace-temps (lieux et dates) et commence à coloniser l’espace, ce dernier contiendra un réseau de biosphère en expansion cosmique, chacune ressemblant à la partie supérieure de la « coupe de champagne » de la figure 6.7. Le bas de chaque biosphère représente le point de départ (lieu et date) de la colonisation. Les « coupes » opaques et translucides correspondent respectivement à une colonisation à 50 % et à 100 % de la vitesse de la lumière. Les chevauchements montrent où les civilisations indépendantes se rencontrent.

Sommes-nous seuls ? L’immense incertitude sur la façon dont ont évolué la vie et l’intelligence semble indiquer que la civilisation qui serait notre plus proche voisine dans l’espace pourrait raisonnablement se trouver n’importe où le long de l’axe horizontal ci-dessus, rendant improbable le fait qu’elle se trouverait dans l’étendue étroite qu’il y a entre le bord de notre galaxie (à environ 1021 mètres) et celui de l’univers (à environ 1026 mètres). S’il y en avait beaucoup plus près que dans cette étendue, il y aurait tant d’autres civilisations supérieures dans notre galaxie que nous les aurions probablement remarquées : en fait, cela suggère donc que nous sommes seuls dans notre univers.

Pour se porter au secours d’un nageur le plus vite possible, un maître-nageur n’ira pas en ligne droite (traits pointillés) mais un peu plus loin sur la plage où il peut se déplacer plus vite que dans l’eau. De la même façon, la trajectoire d’un rayon lumineux présente un certain angle pour rejoindre sa destination le plus vite possible.

Quantités approximatives de matière contenues dans les entités de notre planète qui ont évolué vers un but, ou ont été conçues dans un but. Les artefacts – immeubles, routes, voitures – semblent en bonne voie de dépasser les entités dues à l’évolution, comme les plantes et les animaux.

Tout objectif ultime d’une IA superintelligente conduit forcément aux sousobjectifs décrits. Mais il y a conflit inévitable entre la conservation de l’objectif et l’amélioration de son modèle du monde, ce qui jette le doute sur le fait qu’elle conservera, en fin de compte, son objectif original à mesure qu’elle deviendra plus intelligente.

Même si l’objectif ultime du robot est seulement de rendre maximal le score en conduisant les moutons du pâturage à la bergerie avant que le loup ne les mange, cela peut conduire à des sous-objectifs d’autoconservation (éviter la bombe), d’exploration (trouver un raccourci) et d’acquisition de ressources (la potion lui permettra de courir plus vite et le revolver de tuer le loup).

Comprendre l’esprit implique de hiérarchiser les problèmes. Ce que David Chalmers appelle les problèmes « faciles » peut être posé sans mentionner l’expérience subjective. Le fait apparent que certains systèmes physiques, mais pas tous, sont conscients suscite trois questions distinctes. Si l’on a une théorie répondant à la question de savoir ce qui définit le « problème assez difficile », celui-ci peut être testé de façon expérimentale. Si cela fonctionne, on peut construire là-dessus de quoi aborder les questions plus coriaces.

Supposons qu’un ordinateur mesure l’information traitée dans votre cerveau et prévoie quelles en sont les parties dont vous êtes conscient selon la théorie de la conscience. Vous pouvez tester scientifiquement cette théorie en vérifiant si les prévisions sont correctes, par comparaison à votre expérience subjective.

Les cortex visuel, auditif, somatosensoriel et moteur sont impliqués respectivement dans la vision, l’audition, le sens du toucher et l’activation motrice – ce qui ne prouve pas que la conscience de la vision, de l’audition, du toucher et des mouvements se situe là. En fait, des recherches récentes suggèrent que le cortex visuel primaire est totalement inconscient, tout comme le cervelet et le tronc cérébral. Avec l’aimable autorisation de www.lachina.com.

Quel est le carré le plus sombre – celui étiqueté A ou B ? Que voyez-vous à droite – un vase, deux femmes ou les deux successivement ? Ce type d’illusions montre que votre conscience visuelle ne peut pas se situer dans vos yeux ou à une autre phase de votre système visuel, car cela ne dépend pas seulement de ce qui trouve sur l’image.

Étant donné un traitement physique qui, avec le temps, transforme l’état initial d’un système en un nouvel état, son information intégrée Φ mesure l’incapacité à diviser le processus en deux parties indépendantes. Si l’état futur de chaque partie ne dépend que de son propre passé, et non de ce qu’a fait l’autre partie, alors Φ = 0 : ce que nous appelons un système est en réalité composé de deux systèmes indépendants qui ne communiquent pas du tout entre eux.

Notre conférence Asilomar de janvier 2017. Elle faisait suite à celle de Porto Rico et a rassemblé un groupe remarquable de chercheurs en intelligence artificielle et autres disciplines annexes. Sur le rang arrière, de gauche à droite : Patrick Lin, Daniel Weld, Ariel Conn, Nancy Chang, Tom Mitchell, Ray Kurzweil, Daniel Dewey, Margaret Boden, Peter Norvig, Nick Hay, Moshe Vardi, Scott Siskind, Nick Bostrom, Francesca Rossi, Shane Legg, Manuela Veloso, David Marble, Katja Grace, Irakli Beridze, Marty Tenenbaum, Gill Pratt, Martin Rees, Joshua Greene, Matt Scherer, Angela Kane, Amara Angelica, Jeff Mohr, Mustafa Suleyman, Steve Omohundro, Kate Crawford, Vitalik Buterin, Yutaka Matsuo, Stefano Ermon, Michael Wellman, Bas Steunebrink, Wendell Wallach, Allan Dafoe, Toby Ord, Thomas Dietterich, Daniel Kahneman, Dario Amodei, Eric Drexler, Tomaso Poggio, Eric Schmidt, Pedro Ortega, David Leake, Sean O hEigeartaigh, Owain Evans, Jaan Tallinn, Anca Dragan, Sean Legassick, Toby Walsh, Peter Asaro, Kay Firth-Butterfield, Philip Sabes, Paul Merolla, Bart Selman, Tucker Davey, ?, Jacob Steinhardt, Moshe Looks, Josh Tenenbaum, Tom Gruber, Andrew Ng, Kareem Ayoub, Craig Calhoun, Percy Liang, Helen Toner, David Chalmers, Richard Sutton, Claudia Passos-Ferriera, Janos Kramar, William MacAskill, Eliezer Yudkowsky, Brian Ziebart, Huw Price, Carl Shulman, Neil Lawrence, Richard Mallah, Jurgen Schmidhuber, Dileep George, Jonathan Rothberg, Noah Rothberg – Rang de devant : Anthony Aguirre, Sonia Sachs, Lucas Perry, Jeffrey Sachs, Vincent Conitzer, Steve Goose, Victoria Krakovna, Owen Cotton-Barratt, Daniela Rus, Dylan Hadfield-Menell, Verity Harding, Shivon Zilis, Laurent Orseau, Ramana Kumar, Nate Soares, Andrew McAfee, Jack Clark, Anna Salamon, Long Ouyang, Andrew Critch, Paul Christiano, Yoshua Bengio, David Sanford, Catherine Olsson, Jessica Taylor, Martina Kunz, Kristinn Thorisson, Stuart Armstrong, Yann LeCun, Alexander Tamas, Roman Yampolskiy, Marin Soljacic, Lawrence Krauss, Stuart Russell, Eric Brynjolfsson, Ryan Calo, ShaoLan Hsueh, Meia Chita-Tegmark, Kent Walker, Heather Roff, Meredith Whittaker, Max Tegmark, Adrian Weller, Jose Hernandez-Orallo, Andrew Maynard, John Hering, Abram Demski, Nicolas Berggruen, Gregory Bonnet, Sam Harris, Tim Hwang, Andrew Snyder-Beattie, Marta Halina, Sebastian Farquhar, Stephen Cave, Jan Leike, Tasha McCauley, Joseph Gordon-Levitt – Arrivés plus tard : Guru Banavar, Demis Hassabis, Rao Kambhampati, Elon Musk, Larry Page, Anthony Romero.


